Deploy CDC pipelines in minutes with Sapper’s in-built templates
One-stop shop for all enterprise-level data replication needs











Deploy CDC pipelines in minutes with Sapper’s in-built templates
One-stop shop for all enterprise-level data replication needs
Change Data Capture (CDC)
Sapper uses the CDC Data Integration approach that allows high-velocity data to achieve reliable, low latency, and scalable data replication using fewer computation resources. Change Data Capture (CDC), enabled companies to deliver new data changes to BI (Business Intelligence) tools and team members in real-time, keeping them up to date.
Companies need access to real-time data streams for Data Analytics. Sapper mainly uses Log-Based CDC to ensure no performance impact on the sources. Only the changed data is transferred for faster performance. CDC excludes the process of bulk data loading by implementing incremental loading of data in nearly real-time.
Sapper CDC engine provides you a rare ability to read newly written data from HDFS volumes and sync it to any target to save a considerable amount of time.
Snapshot: Initial snapshot of a database’s current state can be taken if a connector is started and not all logs still exist. Typically, this is the case when the database has been running for some time and has discarded transaction logs that are no longer needed for transaction recovery or replication. There are different modes for performing snapshots.
Filters: You can configure the set of captured schemas, tables and columns with include/exclude list filters.
Masking: The values from specific columns can be masked, which contains sensitive data.
Monitoring: Most connectors can be monitored by using JMX.
Message Transformations: Message transformations can be done for Message routing, Content-based routing, and Filtering.

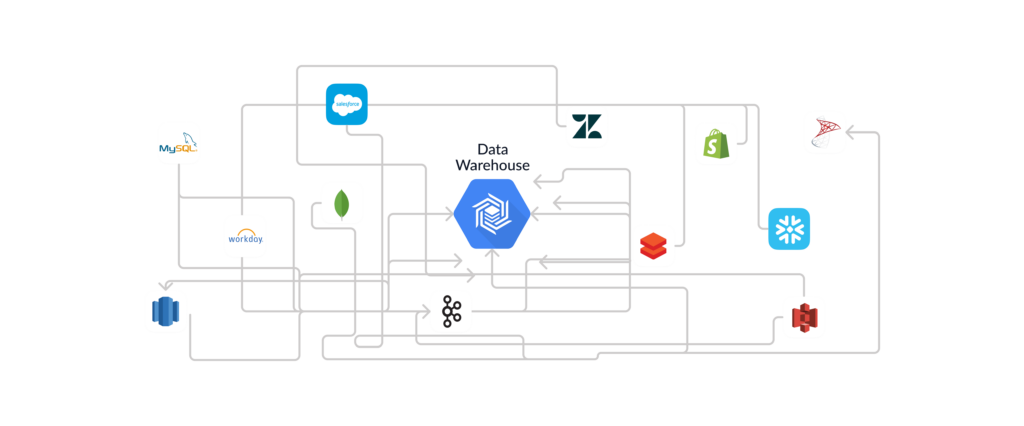
Ingest data from any source to any destination
Ingest data from any source to any destination
Fully Automated and Reliable Data Pipelines for Faster Analytics
Sapper’s fully managed and automated data pipeline loads all your data to the warehouse or data lakes at scale in real-time, ready for analysis.
Fully Automated and Reliable Data Pipelines for Faster Analytics
Sapper’s fully managed and automated data pipeline loads all your data to the warehouse or data lakes at scale in real-time, ready for analysis.
Change Data Capture (CDC)
Sapper uses the CDC Data Integration approach that allows high-velocity data to achieve reliable, low latency, and scalable data replication using fewer computation resources. Change Data Capture (CDC), enabled companies to deliver new data changes to BI (Business Intelligence) tools and team members in real-time, keeping them up to date.
Companies need access to real-time data streams for Data Analytics. Sapper mainly uses Log-Based CDC to ensure no performance impact on the sources. Only the changed data is transferred for faster performance. CDC excludes the process of bulk data loading by implementing incremental loading of data in nearly real-time.
Sapper CDC engine provides you a rare ability to read newly written data from HDFS volumes and sync it to any target to save a considerable amount of time.
Snapshot: Initial snapshot of a database’s current state can be taken if a connector is started and not all logs still exist. Typically, this is the case when the database has been running for some time and has discarded transaction logs that are no longer needed for transaction recovery or replication. There are different modes for performing snapshots.
Filters: You can configure the set of captured schemas, tables and columns with include/exclude list filters.
Masking: The values from specific columns can be masked, which contains sensitive data.
Monitoring: Most connectors can be monitored by using JMX.
Message Transformations: Message transformations can be done for Message routing, Content-based routing, and Filtering.
Real-time data replication with CDC
Living in a world of delayed data means making business decisions with old information. You need data replication solutions that capture and reflect data changes to your analytics and reporting layer as they happen. Sapper Data Movement Platform is a highly versatile solution that helps you build data pipelines that share changes to application data as it occurs. Sapper’s real-time replication ensures that databases are in-sync for reporting, analytics, and data warehousing. You can replicate changes as they happen across relational databases, streaming frameworks, hierarchical data stores, and the cloud. Support a variety of architectures and topologies. Sapper’s resilient data delivery guarantees that you never experience interruptions in your data flow. With Sapper, worry about your business and not your systems. Get the changes you need in real-time without overloading networks or affecting performance. Sapper will help you to build real-time streaming data pipelines to unlock real-time insights.