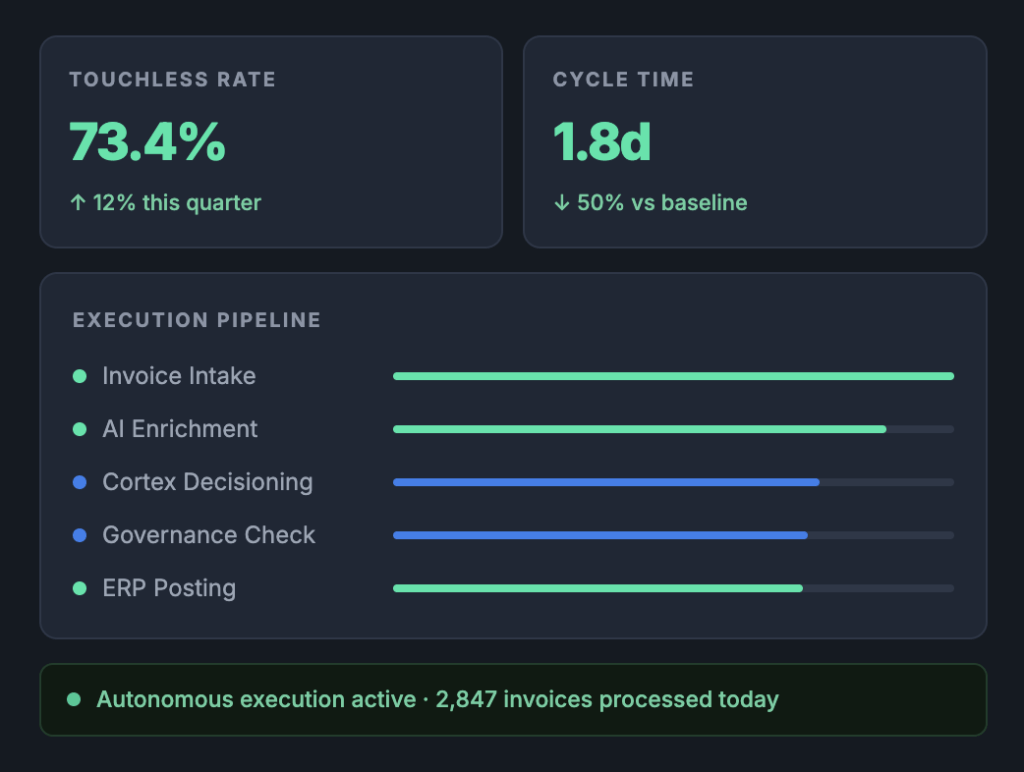
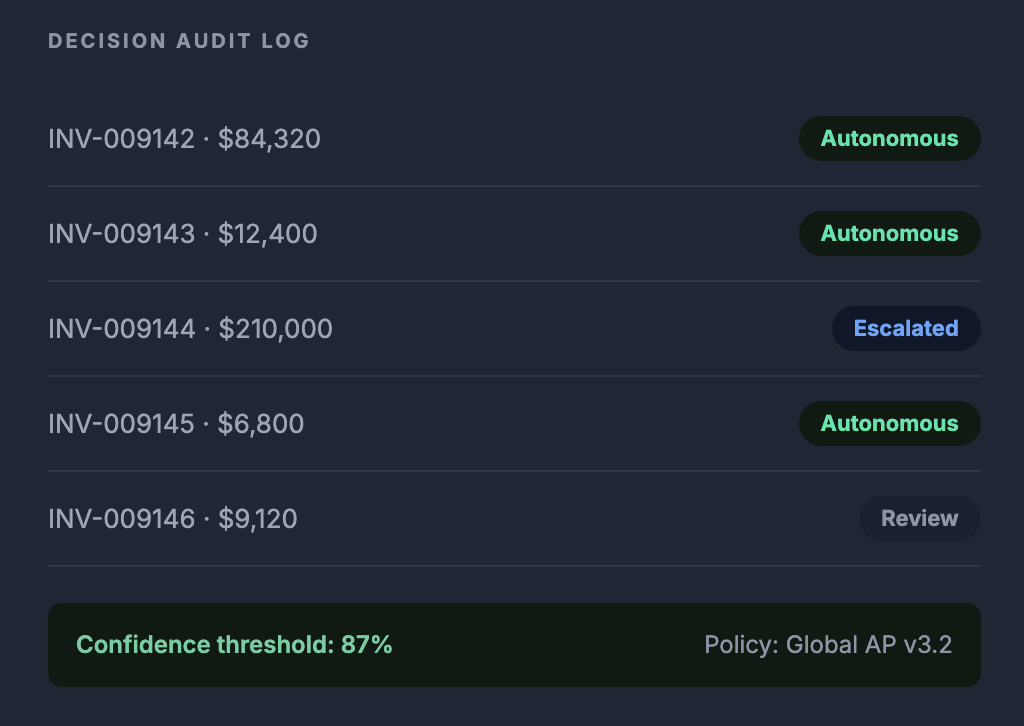
- Products⚡Autonomous AP PlatformThe AI Execution Layer for Autonomous AP. Transform invoice processing from workflow automation into governed autonomous execution.Explore Capabilities →→Transaction Integrity Intelligence→Autonomous Exception Resolution→Intelligent Matching & Validation→Governance & Explainability→InsightX Operational Intelligence🔗Agentic Orchestration PlatformThe Enterprise Orchestration Layer for Agentic Operations. Connect systems, coordinate stakeholders, launch AI agents, govern workflows and orchestrate enterprise execution.Explore Capabilities →→Build Workflows→Launch AI Agents→Govern Access
- Solutions🏢Enterprise APFor CFOs, Controllers and AP Directors. AP automation has not delivered trusted touchless execution.Explore Solution →🌐Shared ServicesFor GBS and Shared Services Leaders. Global process inconsistency and exception backlogs.Explore Solution →⚙️BPO & Managed ServicesFor BPO Executives and Service Delivery Leaders. Labor-based delivery limits margin and scalability.Explore Solution →🤖Agentic OrchestrationFor CIO, COO, AI Transformation. AI agents are hard to orchestrate across systems safely.Explore Solution →
- Integrations
- Resources🔒Trust & SecurityLearn how we protect your data and infrastructure. Security, compliance, and privacy information.View →❓FAQFind answers to common questions about our platform. Get quick guidance on setup and usage.View →📚Learning CenterExplore guides, tutorials, and best practices. Learn how to maximize AP automation efficiency.Notify →Coming Soon✍️BlogInsights on finance operations and automation trends. Industry updates, tips, and expert perspectives.Notify →Coming Soon📰NewsStay informed about company announcements and releases. Product updates, partnerships, and milestones.View →
- Company🏢AboutLearn about Sapper's mission and vision for finance. Driving innovation in modern finance operations.View →👥LeadershipMeet the team behind Sapper's vision and growth. Driving innovation in enterprise AP automation.View →✉️ContactConnect with our team for assistance and guidance. Product, partnership, and support inquiries worldwide.View →
- Products⚡Autonomous AP PlatformThe AI Execution Layer for Autonomous AP. Transform invoice processing from workflow automation into governed autonomous execution.Explore Capabilities →→Transaction Integrity Intelligence→Autonomous Exception Resolution→Intelligent Matching & Validation→Governance & Explainability→InsightX Operational Intelligence🔗Agentic Orchestration PlatformThe Enterprise Orchestration Layer for Agentic Operations. Connect systems, coordinate stakeholders, launch AI agents, govern workflows and orchestrate enterprise execution.Explore Capabilities →→Build Workflows→Launch AI Agents→Govern Access
- Solutions🏢Enterprise APFor CFOs, Controllers and AP Directors. AP automation has not delivered trusted touchless execution.Explore Solution →🌐Shared ServicesFor GBS and Shared Services Leaders. Global process inconsistency and exception backlogs.Explore Solution →⚙️BPO & Managed ServicesFor BPO Executives and Service Delivery Leaders. Labor-based delivery limits margin and scalability.Explore Solution →🤖Agentic OrchestrationFor CIO, COO, AI Transformation. AI agents are hard to orchestrate across systems safely.Explore Solution →
- Integrations
- Resources🔒Trust & SecurityLearn how we protect your data and infrastructure. Security, compliance, and privacy information.View →❓FAQFind answers to common questions about our platform. Get quick guidance on setup and usage.View →📚Learning CenterExplore guides, tutorials, and best practices. Learn how to maximize AP automation efficiency.Notify →Coming Soon✍️BlogInsights on finance operations and automation trends. Industry updates, tips, and expert perspectives.Notify →Coming Soon📰NewsStay informed about company announcements and releases. Product updates, partnerships, and milestones.View →
- Company🏢AboutLearn about Sapper's mission and vision for finance. Driving innovation in modern finance operations.View →👥LeadershipMeet the team behind Sapper's vision and growth. Driving innovation in enterprise AP automation.View →✉️ContactConnect with our team for assistance and guidance. Product, partnership, and support inquiries worldwide.View →