<< Back

Migrating data from Mongo Db to Single Store using the Sapper Data Movement Platform
August 31, 2023
The Sapper Data Movement Platform enables data migration to various heterogeneous data stores. It is secure, reliable, and easy to use. Once the user selects the source and target data stores, the system automatically discovers the schema, processes the snapshot, and captures the streaming data changes (both schema and data).
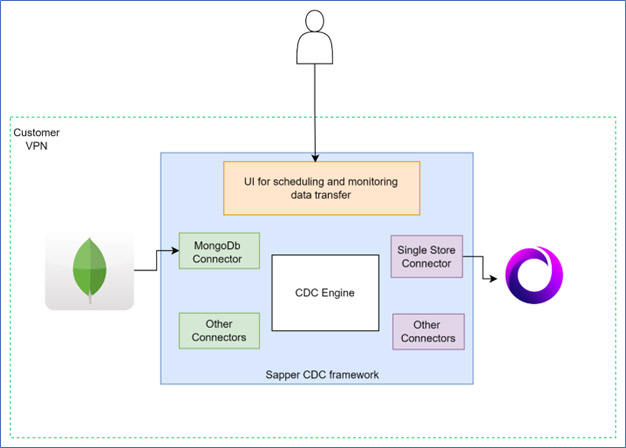
The system has several components – the source data connectors, the sink connectors, the staging area, and processors for schema discovery, data transformation, and validation.
Some of the key features of the platform are:
Security
The data stays on the customer premises (within their virtual network). All data transfer happens within this customer-specified network. The customer controls the access and retention period of both data and logs.
Performance and reliability
The CDC framework reads data from WAL (Write Ahead Log of the database) instead of a live database. Online transactions do not suffer performance degradation because of this.
The system is optimized for minimal resource usage. Furthermore, users can also configure resource usage constraints at deployment time.
The system is reliable – even in case of system crashes, it ensures no data loss.
Ease of use
Integration with the Sapper Data Movement Platform is easy. Both UI and command line options are available. Adding and removing data sources/destinations and scheduling data transfers can be done with a click. Users can control the data migration by pausing or stopping the process on error.
Writing to staging
Before writing to the destination database, the data is stored in a staging area for further processing. This will be deleted when the data is transferred successfully. Customers can also opt for the retention period of this temporary data.
Data Mapping and Transformation Capability
To store MongoDB JSON structure records in a Single Store, the first-level fields of the document are mapped into columns. Inner levels are stored as JSON fields.
Customers can change the type of column in the destination database (Single Store) at the start of the data migration. They also can drop out columns from the destination.
Monitoring
Users can monitor the system’s progress and performance through the metrics dashboard.
Guide to data migration from MongoDB to Single Store
This section will focus on the data transfer process from MongoDB to Single Store.
Configuring the source database
1. Select MongoDB as the source application and click Next.

2. Fill in the source and target connection information.
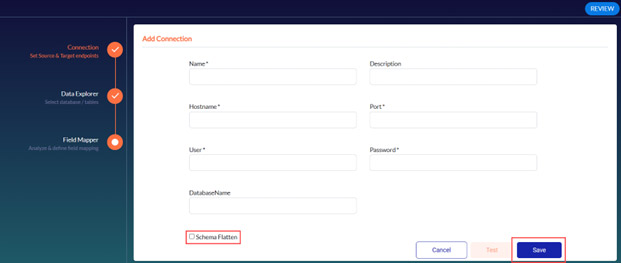
Note: The Schema Flatten feature allows you to flatten complex data schemas of the selected field at the first level.
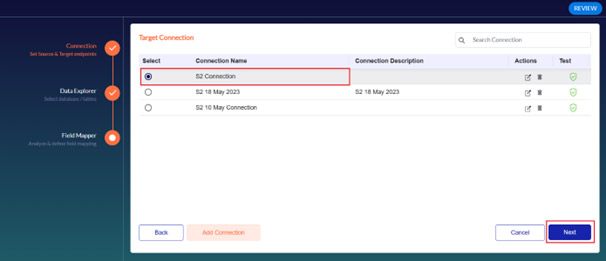
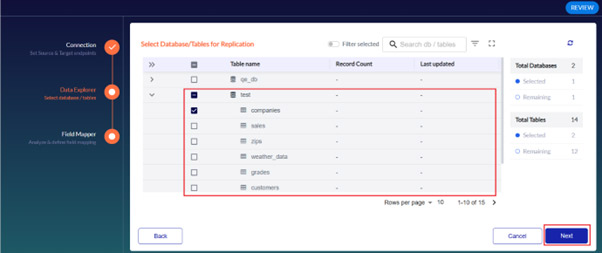
3. Select the database or table you wish to export for replication and click Next.
Data Transformation
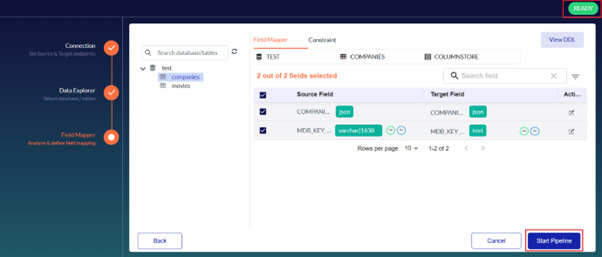
Field Mapper facilitates mapping column data types between the source and the target. The data transferred from the source to the target will be accurate and usable.
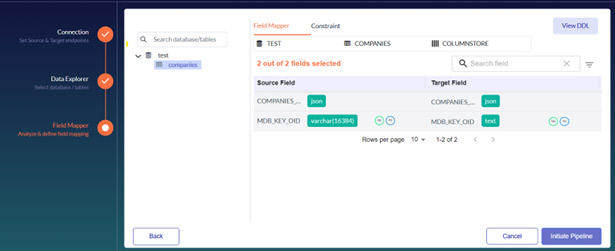
You can view the primary and shared key constraints using the Constraint tab. You can edit them according to your business needs and click Apply Changes. You can also view DDL statements.
Starting the data migration process
- Click the Start Pipeline button to initiate the Snapshot and CDC process to migrate data from source to target tables.