
<< Back

CaTT: Cascading Table Transformer Auto Annotation Engine – A Blog on Unsupervised Learning
August 25, 2023
Need for an Auto Annotation Engine
For a variety of data extraction and classification tasks, the Sapper Data Science team trains many models. We utilize Supervised Learning (SL), a paradigm of machine learning in which models learn from the inputs and outputs we provide them with. Once they learn a pattern, similar data can be predicted.
However, the disadvantages of supervised learning are significant, especially in an industry where speed and cost are important factors. We observed the following disadvantages of supervised learning:
- A longer delivery time – Since SL requires manual annotation of input and output data to create training data, the delivery time is longer.
- High cost and manual effort – Manual annotation requires domain experts since the data might be related to different industries that are not easily understood.
- Issue in Modelling Tables – Table Extraction is an integral part of document extraction and analysis irrespective of the industry. Since these tables tend to be structured, it makes sense to utilize unsupervised learning to solve the problem, since the model can understand the structure without needing training data.
We developed an Unsupervised Learning (UL) approach to form and table annotation; Ideally, this approach can replace manual annotation input and output for a use case. It assumes the following data sets:
- Historical Data from the client – Historical input and output. For example, input PDF and output Excel.
- Staging Data – If the client expects extraction headers to be mapped to standard headers, the framework will also accept staging data.
Architecture and design
This diagram illustrates the framework architecture.
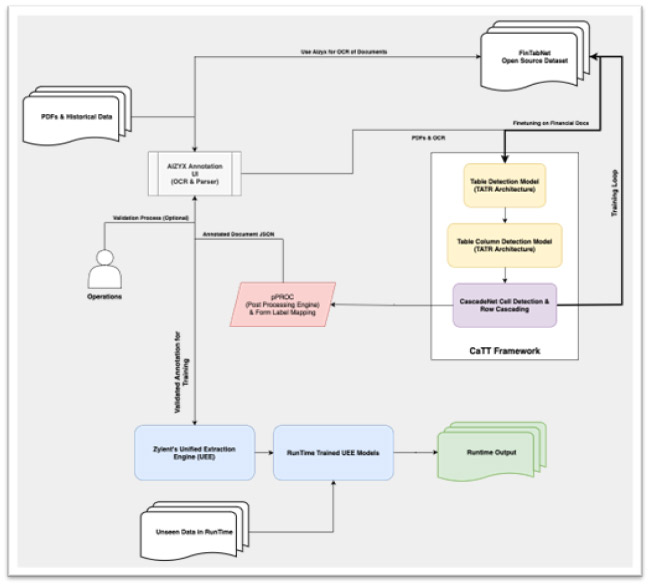
For references, we have drawn inspiration from the following open-source repositories and papers:
- Table Transformer (TATR, Microsoft) – Repository
- Cascade Net – Repository, Published Paper
- FinTabNet Dataset – AI
The following highlights the specific novelty of our framework:
- Modification to TATR:
- The runtime component of TATR has been completely rewritten, and we have replaced the obsolete DETR Feature Extractor with a more robust Auto Extractor from Hugging Face (HF).
- TATR originally used Google Tesseract for OCR; however, we developed our own OCR engine and parser to replace it.
- Inspiration from CascadeNet:
- Rather than using CascadeNet directly to recognize the structure of tables, we utilize a specific CascadeNet component that identifies each cell.
- In addition to changing the architecture of the models used by CascadeNet, we have also improved its object detection functionality, despite the technical aspects.
- By cascading cells into rows, these cells assist us in identifying rows.
- PProc:
- A set of mathematical rules has been developed using statistics for the coordinates of cells and words to automate the completion of columns and rows; this involves filling in information that has been missed from TATR and CascadeNet.
- In addition, we have developed rules for mapping extracted column headers to the standard labels based on the historical data.
- In this module, we also handle overlapping substructures of the cascade output; this includes the splitting and merging of rows.
- Finally, we reverse map the form fields using fuzzy matching.
Our training pipeline has also been improved; instead of training just the transformer component, as is typically done in this industry, we have trained the framework. The diagram illustrates this as well.
Following is a summary of the overall process:
- The documents are selected, and we assume that the historical output is available.
- PDF and OCR files are passed through our OCR engine, and we input the PDF and OCR files to CaTT to automate the process of table annotations.
- The model 1 detects the table outline – the maximum height and width of the table.
- In Model 2, the table’s columns are detected using Modified TATR.
- Model 3 detects cells using CascadeNet and cascades them for row generation.
- The post-processing engine (pPROC) takes the output and applies several rules to ensure that the output table is complete, and all cells are present.
- we perform a Fuzzy Reverse Mapping based on the output data and OCR results to provide form annotations.
- In the final step, if we have staging data, we map the extracted labels to standard labels.
Advantages of CaTT
We have observed multiple benefits to this architecture through testing. Among these benefits are:
Higher Accuracy than Individual Components
The performance of our framework on baseline databases is much higher than the performance of current SOTA architectures such as CascadeNet, GraphNet, or TATR alone.
For example, with our novel modified training process on CaTT on FinTabNet, we achieved ~7% higher accuracy numbers on the dataset than with individual components.
Higher Speed than Competitors
Even though 75% of the architecture uses CNet and pProc (not deep learning-based models), we are able to achieve higher speeds than other architectures.
Baseline Observations: CaTT offers a significant advantage. CaTT can auto-annotate a single document in 3 seconds. When compared to manual annotation, which takes 15 minutes for a single document.
Less Manual Effort
When the operation team of a particular domain performs an optional validation process, CaTT still reduces manual effort by at least 75%. This optional validation process would include a manual oversight of the output to ensure that everything is as it should be in testing, we have found that this process only requires 5% of the manual effort required to annotate the document.
Domain-Independent
As part of its training, TATR uses PubMed – an open collection of around 1 million+ documents containing tables of all kinds. CascadeNet is an object detection approach to cell extraction, so it does not depend on the data domain; pProc is a statistical approach that does not consider the source of the document.
The CaTT is therefore domain independent in all respects; however, to improve performance, we can always finetune using public data of any domain and use the finetuned mode, as shown in the design document.
Conclusion
Here, the development, design, and use case of an auto annotation engine using UL are discussed. We refrain from providing deeper technical details but would be happy to discuss the same if someone is interested!